Baleen Components
Baleen's objective is simple: given an OPML file of RSS feeds, download all the posts from those feeds and save them to MongoDB storage. While this task seems like it could be easily completed with a single function, once you start integrating the parts of the program, things get more complex. The following component architecture describes how we've put together Baleen:
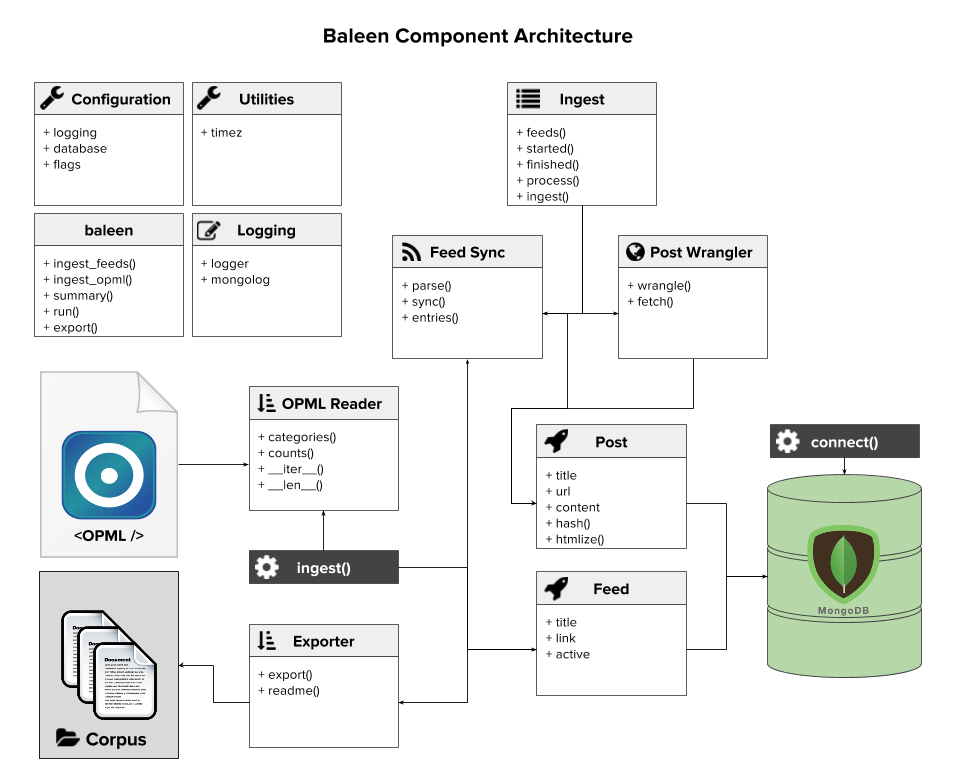
There are three main parts to the component architecture:
- Interacting with the local disk: importing OPML and exporting a corpus.
- Interacting with the MongoDB storage of posts.
- Fetching data from both the RSS feeds as well as the complete web page.
Additionally there are utilities, configuration, and logging as well as the command line program that uses commis, but those are pretty standard and are not specific to Baleen. In the next sections we'll look at and describe the operation of each of these main blocks of code.
MongoDB Models
The central part of the operation of Baleen revolves around the interaction with MongoDB. Baleen uses mongoengine as an ODM to provide models for inserting documents into collections. There are two primary models:
Feed: maintains information about an RSS or Atom feed.Post: a document that has been syndicated by a feed.
Hopefully the relationship is clear: a Feed is a listing of Post documents. Our collection objective is the HTML content of a Post and we use the Feed to obtain the Post rather than web scraping.
Note that these models do nothing except manipulate their data store and read and write to the database. Methods for ingestion, wranging, or fetching the full web page wrap their respective models. E.g. you wouldn't do Feed.sync() to collect the latest RSS feed, instead you would use some Sync object and pass it a feed: Sync(feed).
Ingestion
The ingestion portion of the Baleen service is the most critical and the requirements are as follows:
- On a routine basis, collect and ingest feeds from MongoDB or an OPML file.
- Synchronize feeds by fetching the latest RSS/Atom from their
xmlUrl. - For each item in the synchronized feed, create and wrangle a post.
- For each post fetch the full HTML from the
htmlUrl. - Be able to track the start/stop/duration of the ingestion for a set of feeds.
- Be able to track the number of errors, posts ingested.
- Allow no duplicate posts to be added to the database.
In order to synchronize feeds, we use the feedparser library and to fetch documents from the web, we use Requests. A single Ingest instance takes as input an iterable of feeds from either MongoDB or from an OPML file. When run it maintains two queues: a feed processing queue and a page processing queue (so that it can be threaded or multiprocessed).
Feed processing is performed by a FeedSync object which takes a single feed as input. The FeedSync object fetches the RSS via feedparser, and iterates through all posts, wrangling them and saving them to Mongo. The PageWrangler object takes a post as input, wrangles the data from a variety of feed types, then fetches the complete web page.
Once the Ingest instance has cleared it's work queue, it logs various information and terminates. Note that the Ingest instance is responsible for error handling and logging, while the sync and fetch utilities must raise exceptions.
Import and Export
The import utility uses an OPMLReader to load and parse the OPML file from disk with Beautiful Soup. The OPML file exposes a tree hierarchy or table of contents structure to the feeds where the first level is a "category" and the secondary level is each RSS/Atom feed item. On import, we simply read the OPML file and add any additional feeds to the MongoDB without duplication. This allows us to maintain a single master list of RSS from multiple OPML files.
Note, we've found that the best way to create OPML files is to use the Feedly app, which allows us to organize our feeds. Under their "organize feeds" section, they also have an Export OPML link (and an import OPML link).
The export utility creates a categorized corpus structure ready for NLTK using the MongoExport class. Each category from the TOC structure of the OPML is a directory in the corpus on disk, then each post is written as an HTML file. The exporter also writes a README file with information about the contents fo the corpus. Key concerns here involve HTML sanitization (removing scripts) and readability (extracting only the text we want to analyze).